

摘要:动态页面爬取在面对静态页面的时候直接查看response一般就是网页的全部代码了,但是动态页面不然,一般动态页面的response再打开的时候和你在网页看的不一样了。实践目标:获取万科百度百科历史版本的历史修改时间,做成图表或者csv文件
近年,网络科技迅猛发展推动网页呈现模式日新月异。对比静态与动态页面,二者反应机制明显不同。静页直接展示网页全码,动页响应则具灵活性百度会收录动态页面吗,不限于显示内容。本篇文章将详细解析动态网页与静态网页之别,并分享动态页面抓取策略及实践案例——获取万科百度百科历次修订时间并进行可视化展示。
动态页面与静态页面的区别
动态页面与静态页面在响应方式方面有着明显差异。静态页面以整体HTML文档返回响应结果,因此可直接浏览获取的所有代码。然而,动态页面的响应则需借助JavaScript实现数据异步请求,进而实时构建页面内容。这使得通过响应直接查看页面的可能性降低,仅能获得初始状态或部分代码,无法全面展示页面全貌。这种差异性对页面爬取提出了挑战,需要采取相应策略及工具进行处理。
动态页面爬取技巧
网页分析要点:首先,对目标网页的页面构造及数据获取途径进行深入剖析至关重要。针对含有动态内容的页面,除了审阅HTML源码外,务必关注其后台数据交互模式,譬如使用哪些方式(如JSON文件)实现数据传输。
利用JSON追踪功能:在处理动态网页时,跟踪JSON文件获取相关数据显得尤为重要。通过对页面载入过程中产生的网络请求进行深入分析,便可准确找出页面数据存储于哪个JSON文件内,从而提取出我们所需要的信息。
用户代理伪装:通过模仿各类浏览器的请求特征,对服务器隐藏真实身份,避免因爬虫程序引发的限制措施。
伪装IP:为规避服务器对大范围爬取行为的IP封锁,建议建立IP池并采用各异的IP地址发起请求以降低被封锁的风险。
Cookie隐蔽性技术:服务器常借助Cookie辨识用户状态,譬如登陆状态。故而,应适时更新Cookie,以维持与服务器间连线畅通,保障数据传输及网页浏览功能顺畅无阻。
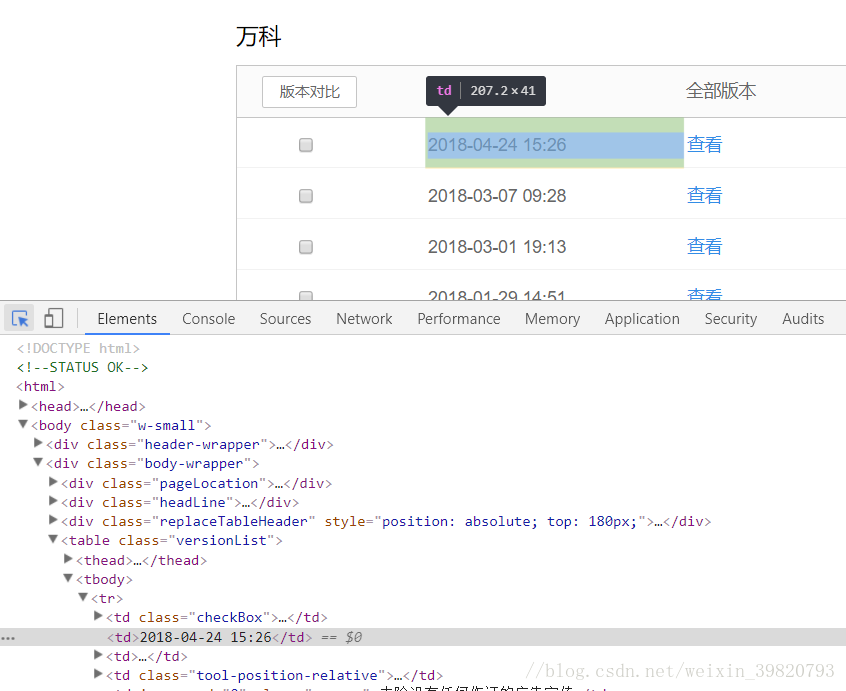
实践目标:获取万科百度百科历史版本的历史修改时间
为了实现实践目标,我们需要经过以下步骤:
网页分析:在研究万科房产百度百科页面时,应先对其结构及数据获取途径进行详细剖析。通过审阅页面源码与网络交互信息,可发现页面运用动态加载技术以获取所需数据。
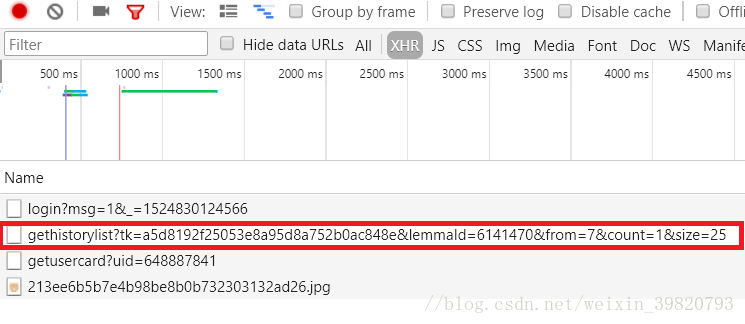
追踪JSON文件:在万科百度百科的页面中,需追踪历史版本的修改时间。通过解析网络请求,可以精准定位包含历史版本信息的JSON文件,提取相应数据。
数据可视化:根据获取之历史编辑时间信息,采用matplotlib库进行可视化处理,进而构造图表展现,让数据能更直观便捷地被理解。
Pandas应用:利用Pandas库,我们能够针对数据进行精细化处理与深度挖掘,比如剖析历史修改时间的分布规律或计算平均修改时间,从而为后续研究提供有力支持。
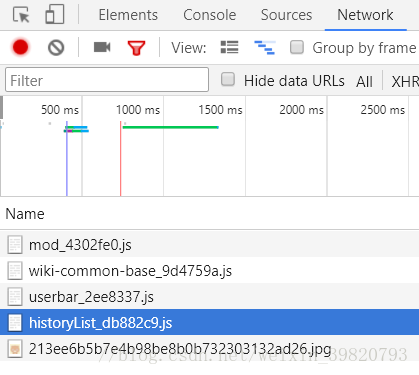
面对动态页面的挑战
在实践过程中,我们可能会遇到一些挑战,例如:
页面数据隐蔽:部分动态页面会将重要数据加密于JSON等格式的文档内,需通过监控网络请求及响应数据以定位并获取所需信息。
数据访问制约因素:某些站点可能施加限制以防止过度数据访问,包括但不限于IP地址屏蔽、验证码措施等,为此需采取有效对策避开此类限制,保证正常的数据收集与加工操作得以顺利运行。
反爬虫措施:为避免遭受爬虫软件困扰,部分网站实施了反爬虫策略,如读取HTTP头部信息及设定访问频次上限等。因此百度会收录动态页面吗,需针对这些措施制定相应对策,以保障数据收集的顺畅无阻。
技巧与应对策略
在处理动态网页爬取时,我们可以运用以下有效的技术手段及策略:
选用适宜框架:选取具备解析动态页面能力的爬虫框架如Scrapy,Selenium等,以提升对其中数据的捕获与处理效率。
构建仿真化的用户活动:模拟实际用户的访问行为,如随机点击、页面滚动等,有效降低被识别的爬虫风险。
随机延迟设定:采用随机延迟策略来处理请求,以模拟真实的用户操作过程,规避可能出现的恶意行为标记问题。
运用代理服务器:利用代理服务器技术,隐藏原始IP地址,有效降低遭受封锁的可能性。
定期调整策略:对爬取策略及相关参数实施周期性调整措施,以适应网页持续变化的反爬虫策略。
结语与展望

动态网页爬取虽具挑战性,却兼具趣味与创新。认真学习并勇于实践,有助于我们更娴熟地运用技能及策略,从而提高爬取效率及成功率。随着网络科技日新月异的进步,我们有信心迎接更多挑战,达成更多爬取目标,为数据分析及应用研究创造更多可能。






